PCA
Principal Component Analysis finds orthogonal directions of maximum variance in the data, enabling dimensionality reduction while retaining as much information as possible.
The examples/pca_clustering_workflow.cpp program projects 10-D Gaussian clusters down to 2-D with PCA and recovers them with KMeans, rendered via SkigenPlot:
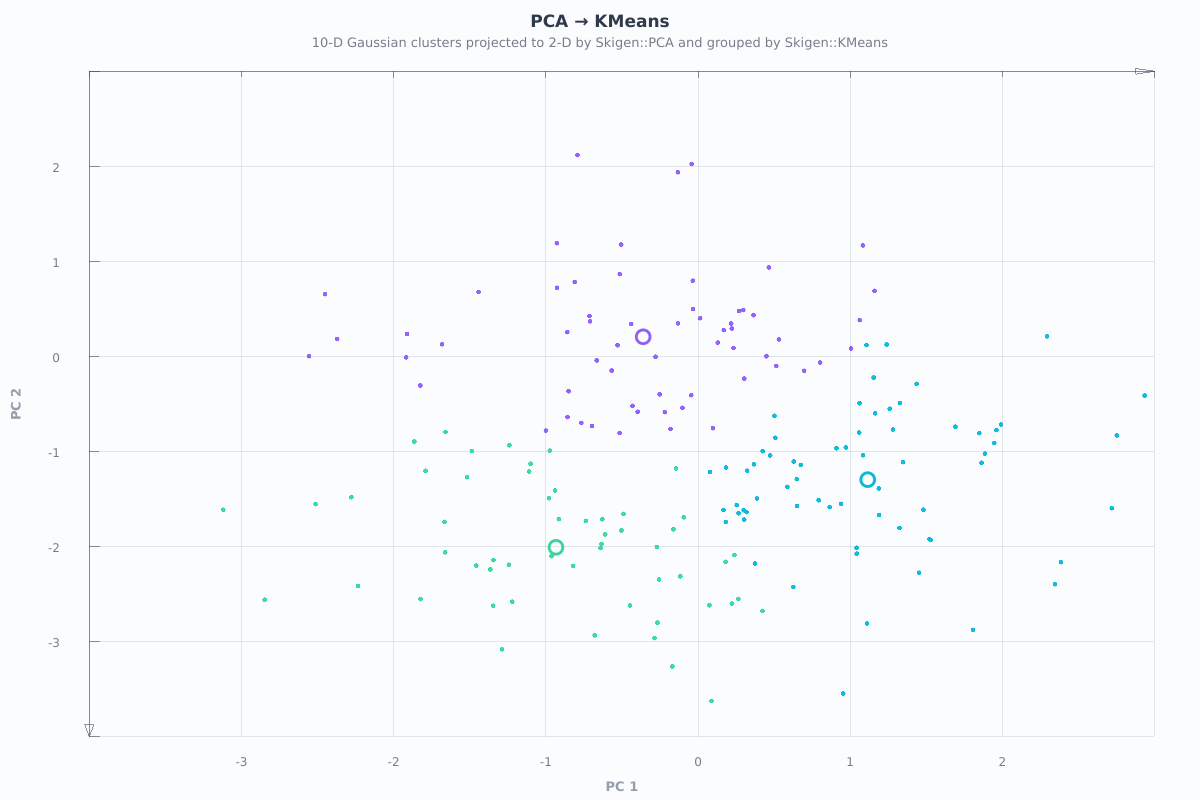
Algorithm
Given an data matrix :
- Center the data: , where is the column-wise mean.
- Compute the SVD of : .
- Truncate to components by keeping only the first columns of (right singular vectors).
The projection onto the -dimensional subspace is:
Explained Variance
The explained variance of the -th component is derived from the singular values:
using degrees of freedom (Bessel's correction), consistent with scikit-learn. The explained variance ratio measures the proportion of total variance captured by each component:
SVD Solvers
The svd_solver parameter selects how the SVD is computed:
"full"(default) — exact decomposition viaEigen::JacobiSVD. Best for small to medium dense data where exactness matters."randomized"— the Halko-Martinsson-Tropp randomized range finder. Draws a Gaussian projection of widthn_components + n_oversamples, runsn_iterQR-stabilised power iterations, then performs a small dense SVD. Much faster than the full SVD when only the top components are needed.
Sparse Input
PCA supports sparse matrices natively via implicit centering. The data is mean-centered through a linear operator
so the sparse matrix is never materialised dense. Sparse fitting always uses the randomized solver — this mirrors scikit-learn, where explicitly centering a sparse matrix would destroy its sparsity. The per-feature mean is computed directly from the sparse column sums.
Key Properties
- PCA always centers the data before decomposition. For data that should not be centered (e.g., TF-IDF), use TruncatedSVD instead.
- The components are ordered by decreasing explained variance.
inverse_transformreconstructs an approximation: .
Mirrors sklearn.decomposition.PCA.
Constructor
Skigen::PCA<Scalar> pca(
Eigen::Index n_components = 0,
std::string svd_solver = "full",
int n_oversamples = 10,
int n_iter = 5,
std::optional<uint64_t> random_state = std::nullopt);
| Parameter | Default | Description |
|---|---|---|
n_components | 0 | Number of components to keep ( = all) |
svd_solver | "full" | "full" (exact) or "randomized" |
n_oversamples | 10 | Extra random dimensions for the randomized solver |
n_iter | 5 | Power iterations for the randomized solver |
random_state | nullopt | Seed for the randomized solver |
Methods
| Method | Description |
|---|---|
fit(X) | Compute the SVD of the centered dense data (full or randomized) |
fit(X_sparse) | Native sparse fit via implicit centering (randomized) |
transform(X) | Project onto the principal components |
fit_transform(X) | Fit and project in one call |
inverse_transform(Z) | Reconstruct from the reduced representation |
Fitted Attributes
| Accessor | Type | Description |
|---|---|---|
components() | MatrixType | Principal axes (rows = components) |
explained_variance() | VectorType | Variance explained by each component () |
explained_variance_ratio() | VectorType | Fraction of total variance per component |
singular_values() | VectorType | Singular values |
mean() | RowVectorType | Per-feature mean |
Example
#include <Skigen/Decomposition>
#include <Eigen/Dense>
#include <iostream>
int main() {
Eigen::MatrixXd X = Eigen::MatrixXd::Random(100, 10);
Skigen::PCA pca(3); // keep 3 components
pca.fit(X);
Eigen::MatrixXd X_reduced = pca.transform(X); // 100 x 3
std::cout << "Explained variance ratio: "
<< pca.explained_variance_ratio().transpose() << "\n";
// Approximate reconstruction
Eigen::MatrixXd X_approx = pca.inverse_transform(X_reduced);
}