KMeans
K-Means partitions samples into clusters by minimizing the within-cluster sum of squared distances (inertia).
The examples/cluster/kmeans.cpp program groups three Gaussian clusters and renders them with SkigenPlot:
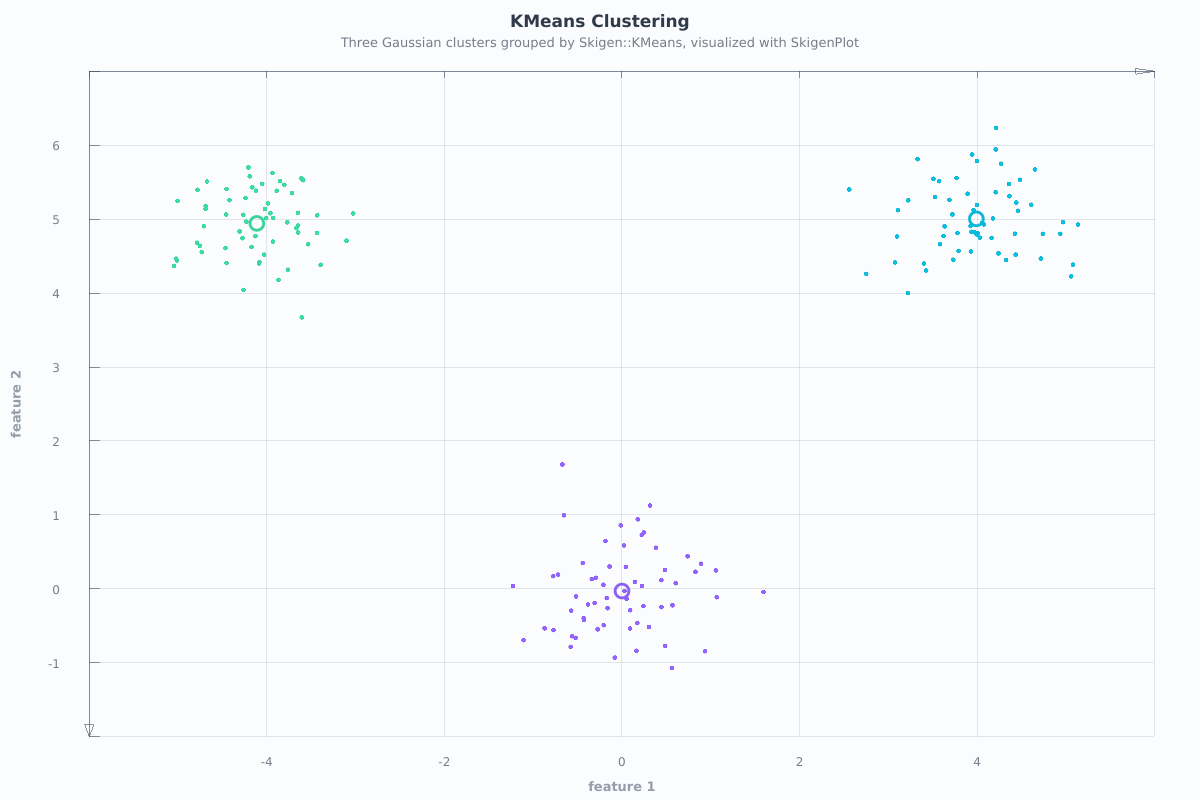
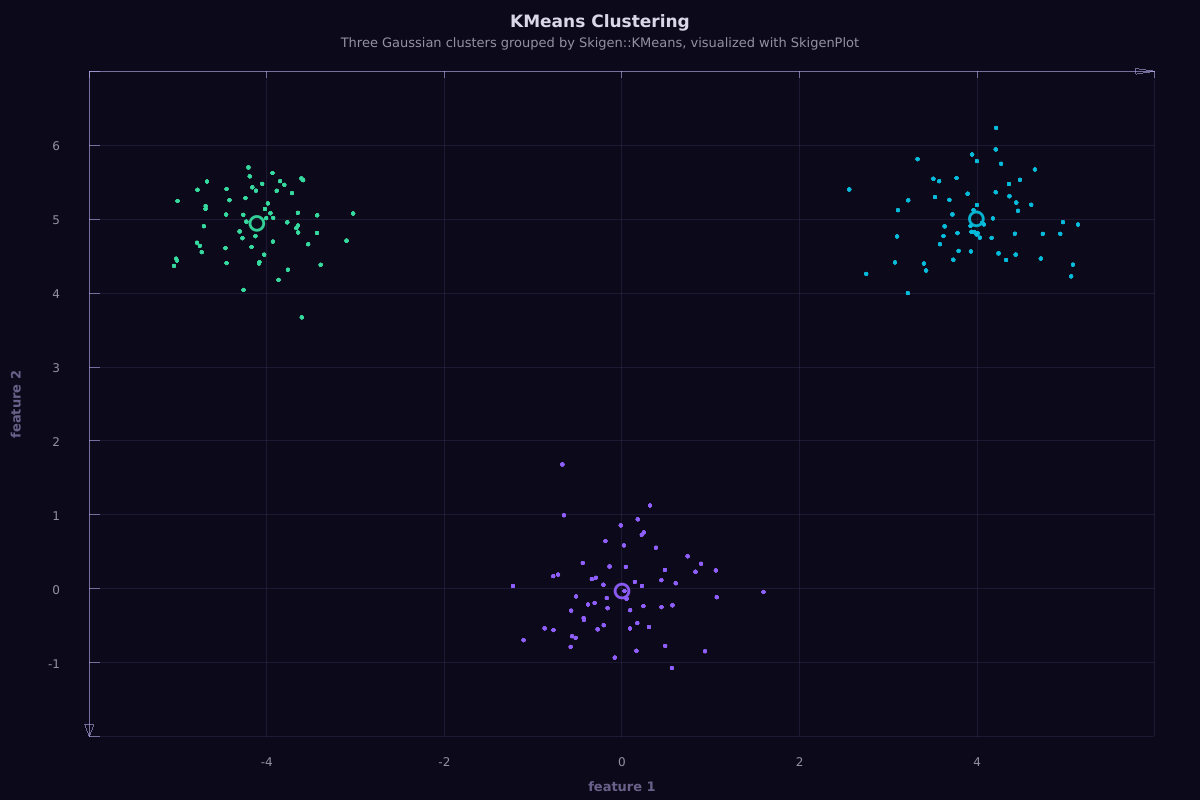
Objective Function
where is the centroid of cluster .
Lloyd's Algorithm
K-Means uses Lloyd's algorithm, which alternates two steps until convergence:
- Assignment: Assign each sample to the cluster with the nearest centroid:
- Update: Recompute each centroid as the mean of its assigned samples:
The algorithm terminates when assignments no longer change or max_iter is reached. The result is a local minimum — n_init independent runs with different initializations are performed, and the solution with the lowest inertia is kept.
k-means++ Initialization
To avoid poor local minima, Skigen uses the k-means++ initialization strategy:
- Choose the first centroid uniformly at random from the data.
- For each subsequent centroid , sample a data point with probability proportional to , where is the distance from to its nearest existing centroid.
This initialization spreads the initial centroids apart, leading to faster convergence and better final solutions (Arthur & Vassilvitskii, 2007).
Computational Complexity
Each iteration of Lloyd's algorithm costs , where is the number of samples, is the number of clusters, and is the number of features.
Mirrors sklearn.cluster.KMeans.
Constructor
Skigen::KMeans<Scalar> km(int n_clusters = 8, int max_iter = 300,
int n_init = 10, unsigned int random_state = 42);
| Parameter | Default | Description |
|---|---|---|
n_clusters | 8 | Number of clusters |
max_iter | 300 | Maximum Lloyd iterations per run |
n_init | 10 | Number of independent initializations (best inertia kept) |
random_state | 42 | Random seed for reproducibility |
Methods
| Method | Description |
|---|---|
fit(X) | Compute K-Means clustering |
predict(X) | Assign each sample to the nearest centroid |
transform(X) | Transform to cluster-distance space ( matrix) |
fit_predict(X) | Fit and return cluster labels |
Fitted Attributes
| Accessor | Type | Description |
|---|---|---|
cluster_centers() | MatrixType | Centroid coordinates () |
labels() | IndexVector | Cluster labels of training data |
inertia() | Scalar | Sum of squared distances to centroids |
n_iter() | int | Number of iterations in the best run |
Example
#include <Skigen/Cluster>
#include <Eigen/Dense>
#include <iostream>
int main() {
Eigen::MatrixXd X = Eigen::MatrixXd::Random(200, 3);
Skigen::KMeans km(4);
km.fit(X);
std::cout << "Inertia: " << km.inertia() << "\n";
std::cout << "Centers:\n" << km.cluster_centers() << "\n";
auto labels = km.predict(X);
}
References
- Arthur, D. and Vassilvitskii, S. (2007). "k-means++: The advantages of careful seeding." Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, 1027–1035.