KMeans
#include <Skigen/Cluster>
template <typename Scalar = double>
class Skigen::KMeans(n_clusters=8, max_iter=300, n_init=10, random_state=42)
K-Means clustering.
The KMeans algorithm clusters data by trying to separate samples in n_clusters groups of equal variance, minimizing the within-cluster sum-of-squares (inertia). Uses k-means++ initialization and Lloyd's iterative algorithm.
Mirrors sklearn.cluster.KMeans.
Parameters:
-
n_clusters : int, default=8 The number of clusters (
int, default8). -
max_iter : int, default=300 Maximum iterations per run (
int, default300). -
n_init : int, default=10 Number of runs with different seeds (
int, default10). -
random_state : unsigned int, default=42 RNG seed (
unsigned int, default42).
Attributes:
-
n_clusters : int The number of clusters.
-
cluster_centers : MatrixType Cluster centers (n_clusters × n_features).
-
labels : IndexVector Labels of each training point from the best run.
-
inertia : Scalar Sum of squared distances to closest cluster center.
-
n_iter : int Number of iterations in the best run.
Methods
SKIGEN_PARAMS()
Compute k-means clustering.
Runs n_init trials of Lloyd's algorithm with k-means++ initialization, keeping the result with the lowest inertia.
Parameters:
- X Training data of shape (n_samples, n_features).
Returns:
- result
Reference to the fitted estimator (
*this).
Throws:
std::invalid_argument— ifn_samples < n_clusters.
fit(X)
Fit k-means on a sparse design matrix without densifying X.
Each squared distance is evaluated via the expansion , where is computed by iterating only over the row's explicit nonzeros (and is precomputed once). Per-iteration center updates accumulate column-sums of the sparse rows assigned to each cluster — again, only over nonzeros. Centroids themselves remain dense.
Mirrors sklearn's KMeans.fit behaviour on sparse input. algorithm selection (only Lloyd implemented), tol, verbose, init=random, init=array are not honoured.
predict(X)
Predict the closest cluster for each row of a sparse X.
predict(X)
Predict the closest cluster each sample belongs to.
Parameters:
- X : MatrixType New data of shape (n_samples, n_features).
Returns:
- result : IndexVector Index of the closest cluster for each sample.
Throws:
std::runtime_error— if the model has not been fitted.
transform(X)
Transform X to a cluster-distance space.
Returns the Euclidean distance from each sample to each cluster center.
Parameters:
- X : MatrixType Data of shape (n_samples, n_features).
Returns:
- result : MatrixType Distance matrix of shape (n_samples, n_clusters).
Throws:
std::runtime_error— if the model has not been fitted.
Example
// KMeans
Skigen::KMeans<double> km(3, /*max_iter=*/300, /*n_init=*/10, /*random_state=*/42);
km.fit(X);
std::cout << "=== KMeans (k=3) ===\n";
std::cout << "Inertia: " << km.inertia() << "\n";
std::cout << "Iterations: " << km.n_iter() << "\n";
std::cout << "Centers:\n" << km.cluster_centers() << "\n\n";
// Predict on new points
Eigen::MatrixXd X_new(3, 2);
X_new << -4.0, 0.0,
4.0, 0.0,
0.0, 5.0;
auto labels = km.predict(X_new);
std::cout << "New point labels: " << labels.transpose() << "\n\n";
Plotting
The figure below is rendered from a registered SkigenPlot-enabled example during the documentation build.
Source example: examples/cluster/kmeans.cpp
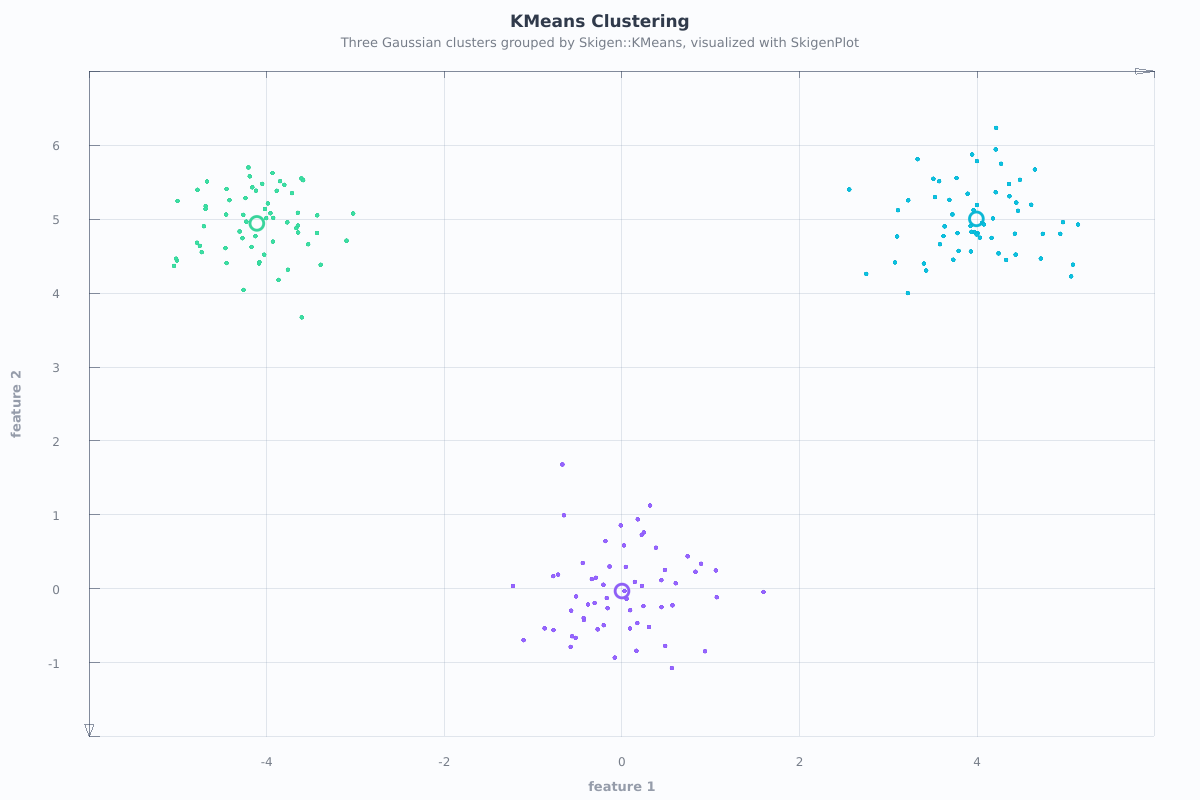
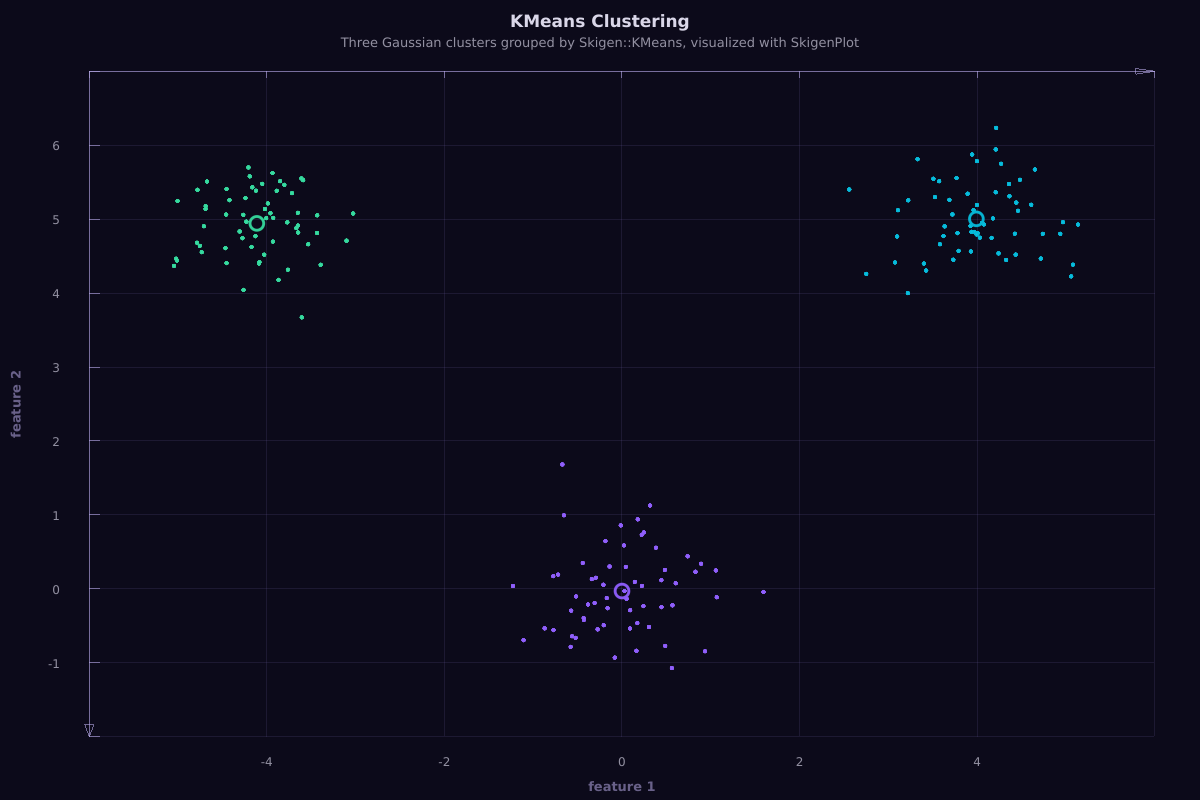
Skigen::Plot::Figure fig;
fig.title("KMeans Clustering")
.caption("Three Gaussian clusters grouped by Skigen::KMeans, visualized with SkigenPlot")
.xlabel("feature 1")
.ylabel("feature 2")
.scatter(X, km.predict(X))
.scatter(km.cluster_centers(), km.predict(km.cluster_centers()),
{.pointSize = 18.0f, .hollow = true});
return argc > 1 ? (fig.saveThemed(argv[1]) ? 0 : 1) : fig.show();