PCA
#include <Skigen/Decomposition>
template <typename Scalar = double>
class Skigen::PCA(n_components=0, svd_solver="full", n_oversamples=10, n_iter=5, random_state=std::nullopt)
Principal component analysis (PCA).
Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower dimensional space. The input data is centered but not scaled for each feature before applying the SVD.
Mirrors sklearn.decomposition.PCA.
Parameters:
-
n_components : Eigen::Index, default=0 Number of components to keep (
IndexType, default0).0means all components are kept. -
svd_solver : std::string, default="full" Solver:
"full"(default, exact JacobiSVD) or"randomized"(Halko-Martinsson-Tropp). Sparse input always uses the randomized path regardless of this setting. -
n_oversamples : int, default=10 Extra random dimensions for the randomized solver (default
10, sklearn parity). -
n_iter : int, default=5 Power iterations for the randomized solver (default
5, sklearn's "randomized" default for small data). -
random_state : std::optional< uint64_t >, default=std::nullopt Optional seed for the randomized solver.
Attributes:
-
n_components : Eigen::Index The actual number of components after fitting.
-
components : MatrixType Principal axes in feature space (n_components × n_features).
-
explained_variance : VectorType Variance explained by each selected component.
-
explained_variance_ratio : VectorType Percentage of variance explained by each selected component.
-
singular_values : VectorType Singular values corresponding to each component.
-
mean : RowVectorType Per-feature empirical mean (1 × n_features).
-
svd_solver : const std::string The configured SVD solver (
"full"or"randomized").
Methods
SKIGEN_PARAMS()
Fit the model with dense X.
Centers the data, then computes the SVD using the configured solver: "full" (exact JacobiSVD) or "randomized" (Halko-Martinsson-Tropp).
Parameters:
- X Training data of shape (n_samples, n_features).
Returns:
- result
Reference to the fitted transformer (
*this).
Throws:
std::invalid_argument— for an unknownsvd_solver.
fit(X)
Fit natively from a sparse design matrix without densifying.
Computes the per-feature mean from the sparse matrix, then runs the randomized SVD against an implicitly-centered linear operator ( ). The sparse input is never materialised dense. Mirrors sklearn's sparse PCA randomized path.
transform(X)
Apply dimensionality reduction to X.
Projects data onto the first n_components principal axes: .
Parameters:
- X : MatrixType Data matrix of shape (n_samples, n_features).
Returns:
- result : MatrixType Transformed data of shape (n_samples, n_components).
Throws:
std::runtime_error— if the model has not been fitted.
inverse_transform(X)
Transform data back to its original space.
Approximately reconstructs: .
Parameters:
- X : MatrixType Transformed data of shape (n_samples, n_components).
Returns:
- result : MatrixType Reconstructed data of shape (n_samples, n_features).
Throws:
std::runtime_error— if the model has not been fitted.
Example
// Reduce to 3 components
Skigen::PCA<double> pca(3);
pca.fit(X_scaled);
Eigen::MatrixXd X_reduced = pca.transform(X_scaled);
std::cout << "=== PCA (10D → 3D) ===\n";
std::cout << "Explained variance ratio: "
<< pca.explained_variance_ratio().transpose() << "\n";
std::cout << "Total variance captured: "
<< pca.explained_variance_ratio().sum() * 100.0 << "%\n";
std::cout << "Singular values: "
<< pca.singular_values().transpose() << "\n";
std::cout << "Reduced shape: " << X_reduced.rows() << " x "
<< X_reduced.cols() << "\n\n";
// Inverse transform — reconstruct approximate original
Eigen::MatrixXd X_approx = pca.inverse_transform(X_reduced);
Plotting
The figure below is rendered from a registered SkigenPlot-enabled example during the documentation build.
Source example: examples/pca_clustering_workflow.cpp
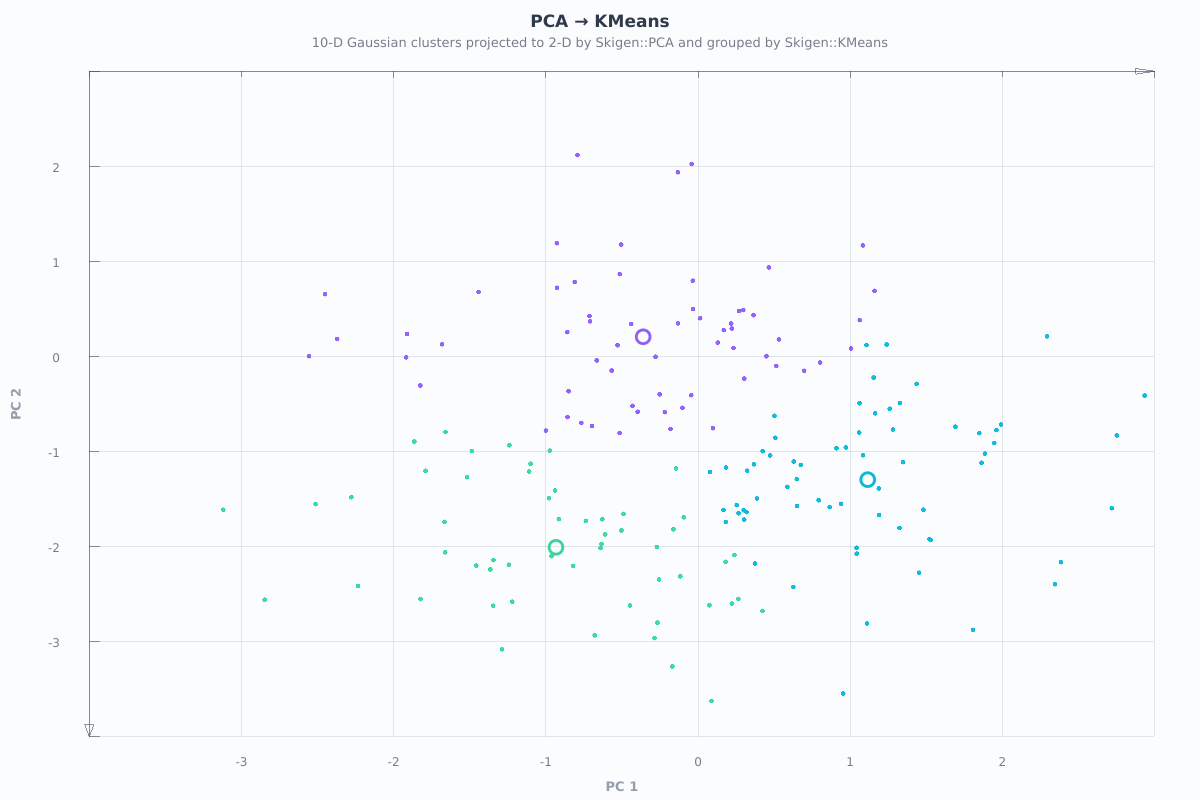
Skigen::Plot::Figure fig;
fig.title("PCA → KMeans")
.caption("10-D Gaussian clusters projected to 2-D by Skigen::PCA and grouped by Skigen::KMeans")
.xlabel("PC 1")
.ylabel("PC 2")
.scatter(X_pca, km.predict(X_pca))
.scatter(km.cluster_centers(), km.predict(km.cluster_centers()),
{.pointSize = 18.0f, .hollow = true});
return argc > 1 ? (fig.saveThemed(argv[1]) ? 0 : 1) : fig.show();